Elder Scrolls 5: Skyrim Special Edition
The Elder Scrolls 5: Skyrim Special Edition es una re-edición del juego de rol de fantasía de mundo abierto The Elder Scrolls 5: Skyrim Legendary... Leer más
xVASynth 2 - SKVA Synth - herramienta de voz en off
-
www.nexusmods.comDescargar
xVASynth 2 - Sintetizador SKVA.
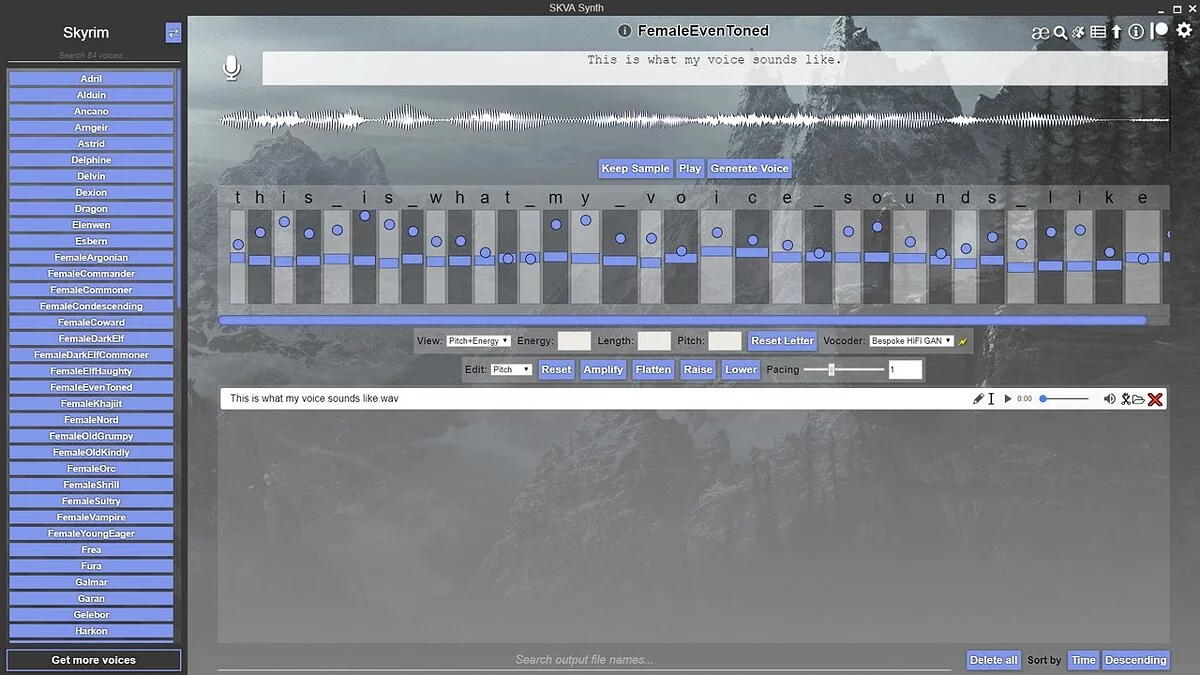
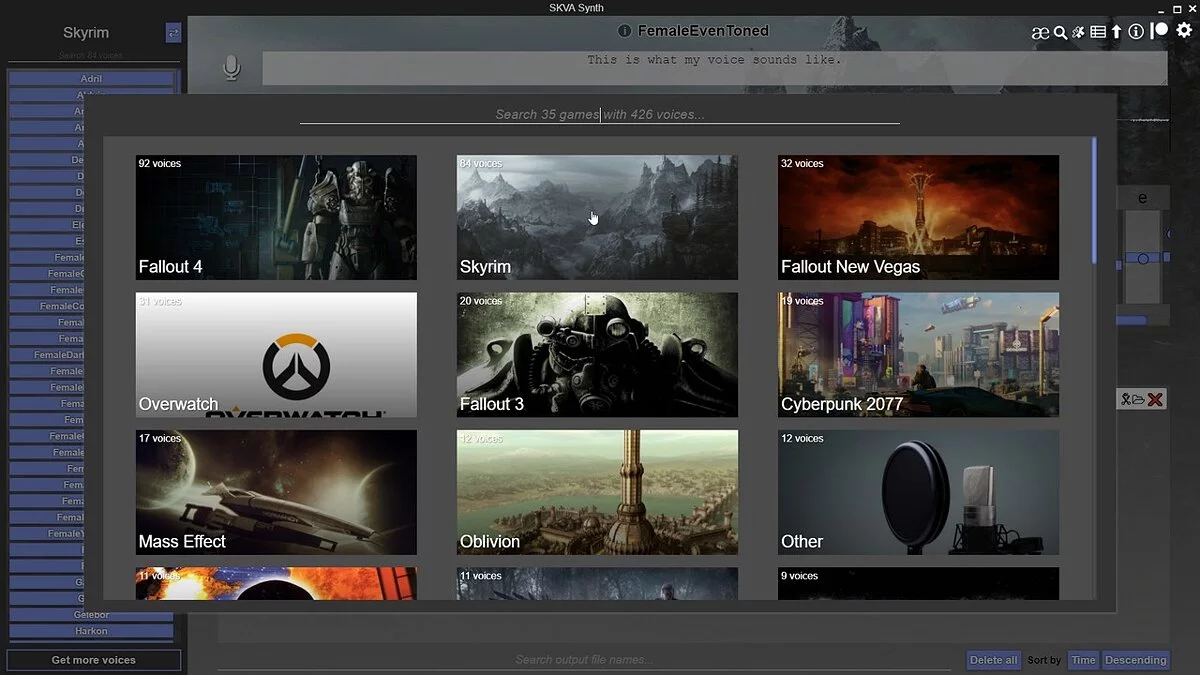
xVASynth es una herramienta de inteligencia artificial para crear locuciones de alta calidad utilizando voces de videojuegos. La aplicación admite cientos de voces en docenas de juegos y proporciona control sobre el tono, la duración y la energía al pie de la letra.
Introducción
xVASynth (o [SK]VASynth, para las voces de Skyrim) es una aplicación de inteligencia artificial que genera líneas de voz en off utilizando voces específicas de videojuegos. Puede convertir texto a voz (TTS) a partir de entrada de texto o voz a voz (S2S) a partir de entrada de audio. La aplicación utiliza modelos FastPitch [1,2], que brindan a los usuarios control artístico sobre el tono, la duración y los valores de energía (solo modelos v2+) para cada letra del audio. También te permiten generar audio con una pronunciación explícita mediante la notación ARPAbet.
El uso de la síntesis neuronal del habla da como resultado voces con un sonido natural, lo cual es muy difícil de lograr usando métodos más tradicionales que implican combinar datos existentes. Esto también significa que se puede generar vocabulario nuevo más allá de lo que los actores de voz ya han leído.

xVASynth 2 — SKVA Synth.
xVASynth — это инструмент искусственного интеллекта для создания высококачественных реплик озвучки с использованием голосов из видеоигр. Приложение поддерживает сотни голосов в десятках игр и обеспечивает управление высотой тона, продолжительностью и энергией с точностью до каждой буквы.
Вступление
xVASynth (или [SK]VASynth, для голосов Skyrim) — это приложение с искусственным интеллектом, которое генерирует реплики озвучки, используя определенные голоса из видеоигр. Он может преобразовывать текст в речь (TTS) из текстового ввода или речь в речь (S2S) из аудиовхода. Приложение использует модели FastPitch [1,2], которые дают пользователям художественный контроль над высотой тона, длительностью и значениями энергии (только модели v2+) для каждой буквы в аудио. Они также позволяют генерировать звук с явно заданным произношением через нотацию ARPAbet.
Использование нейронного синтеза речи приводит к естественному звучанию голоса, что очень сложно сделать с помощью более традиционных методов, включающих объединение существующих данных. Это также означает, что может быть сгенерирован новый словарный запас помимо того, что актеры озвучивания уже прочитали.
Enlaces útiles: